部署与推理优化
让大模型跑得更快、更省
🎯 核心挑战
部署难点
| 挑战 | 问题 | 解决方案 |
|---|---|---|
| 显存占用 | 7B模型需14GB+ | 量化压缩 |
| 推理速度 | 自回归生成慢 | KV Cache、批处理 |
| 成本 | GPU昂贵 | CPU推理、边缘部署 |
| 延迟 | 首Token时间长 | 推测解码 |
🗜️ 模型量化
量化类型
| 类型 | 精度 | 显存节省 | 精度损失 |
|---|---|---|---|
| FP32 | 32位 | 基准 | 无 |
| FP16/BF16 | 16位 | 50% | 极小 |
| INT8 | 8位 | 75% | 小 |
| INT4 | 4位 | 87.5% | 中等 |
| INT2 | 2位 | 93.75% | 较大 |
量化方法
| 方法 | 原理 | 适用场景 |
|---|---|---|
| PTQ(训练后量化) | 直接量化已训练模型 | 快速部署 |
| QAT(量化感知训练) | 训练时模拟量化 | 追求精度 |
| GPTQ | 基于Hessian的逐层量化 | 4-bit高精度 |
| AWQ | 激活感知量化 | 保护重要权重 |
| GGUF | llama.cpp格式 | CPU推理 |
BitsAndBytes量化
python
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
# 8-bit量化
model_8bit = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
load_in_8bit=True,
device_map="auto"
)
# 4-bit量化(NF4)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True
)
model_4bit = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto"
)GPTQ量化
python
from transformers import AutoModelForCausalLM, GPTQConfig
gptq_config = GPTQConfig(
bits=4,
dataset="c4",
tokenizer=tokenizer
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=gptq_config,
device_map="auto"
)🚀 推理优化
来源:FlashAttention 详解 | FlashAttention V2 | vLLM 官方博客 | PagedAttention 论文
FlashAttention
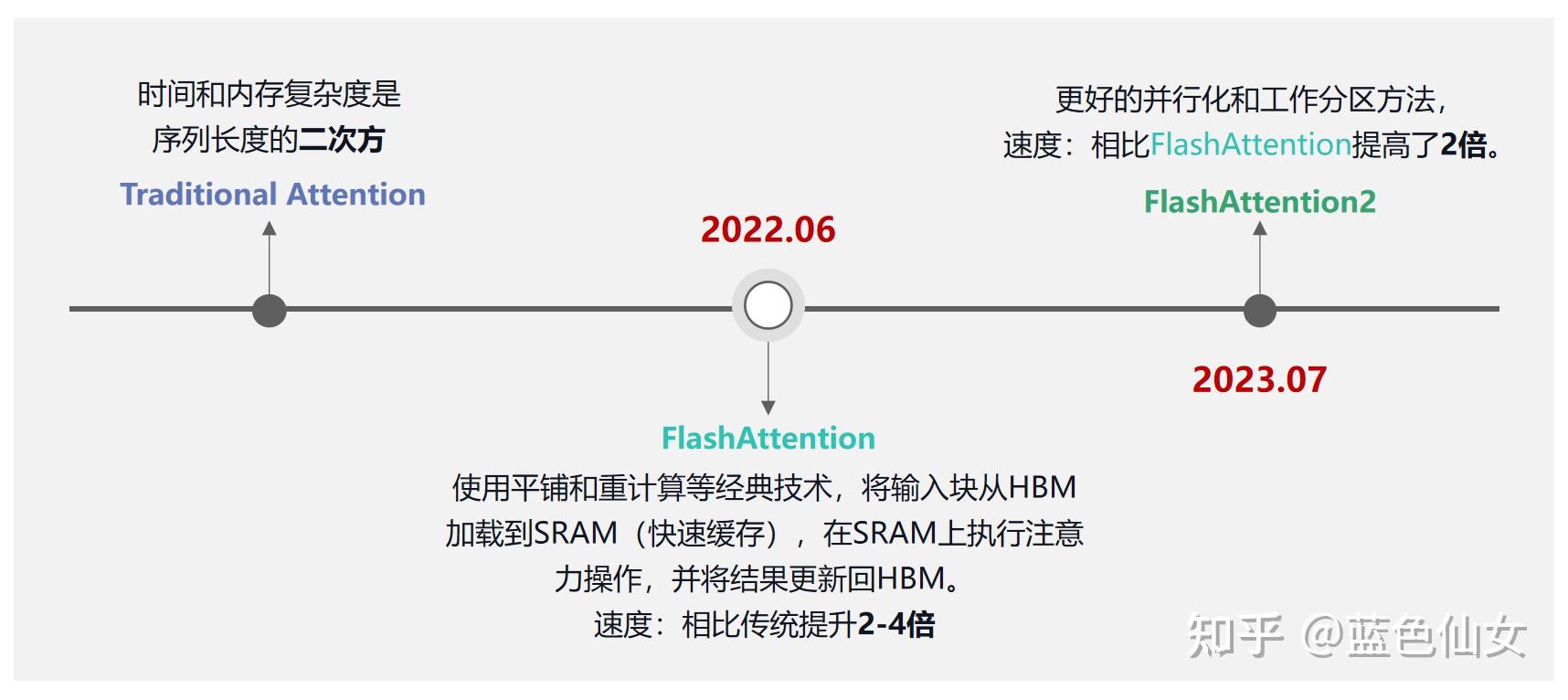 FlashAttention 分块计算原理
FlashAttention 分块计算原理
FlashAttention 是一种 IO 感知的注意力计算方法,已广泛应用于 GPT-3/4、Llama2、Falcon2 等 LLM。
核心技术:
| 技术 | 说明 |
|---|---|
| Tiling(分块) | 将 Q、K、V 分成小块放入 SRAM |
| Kernel Fusion | 多个计算步骤合并为单一 CUDA kernel |
| Recomputation | 反向传播时重算中间结果,用计算换存储 |
| Online Softmax | 分块计算 Softmax,无需完整注意力矩阵 |
效果:
- HBM 读写量从 $O(N^2)$ 降到 $O(N)$
- 训练/推理速度提升 2-4×
vLLM高性能推理
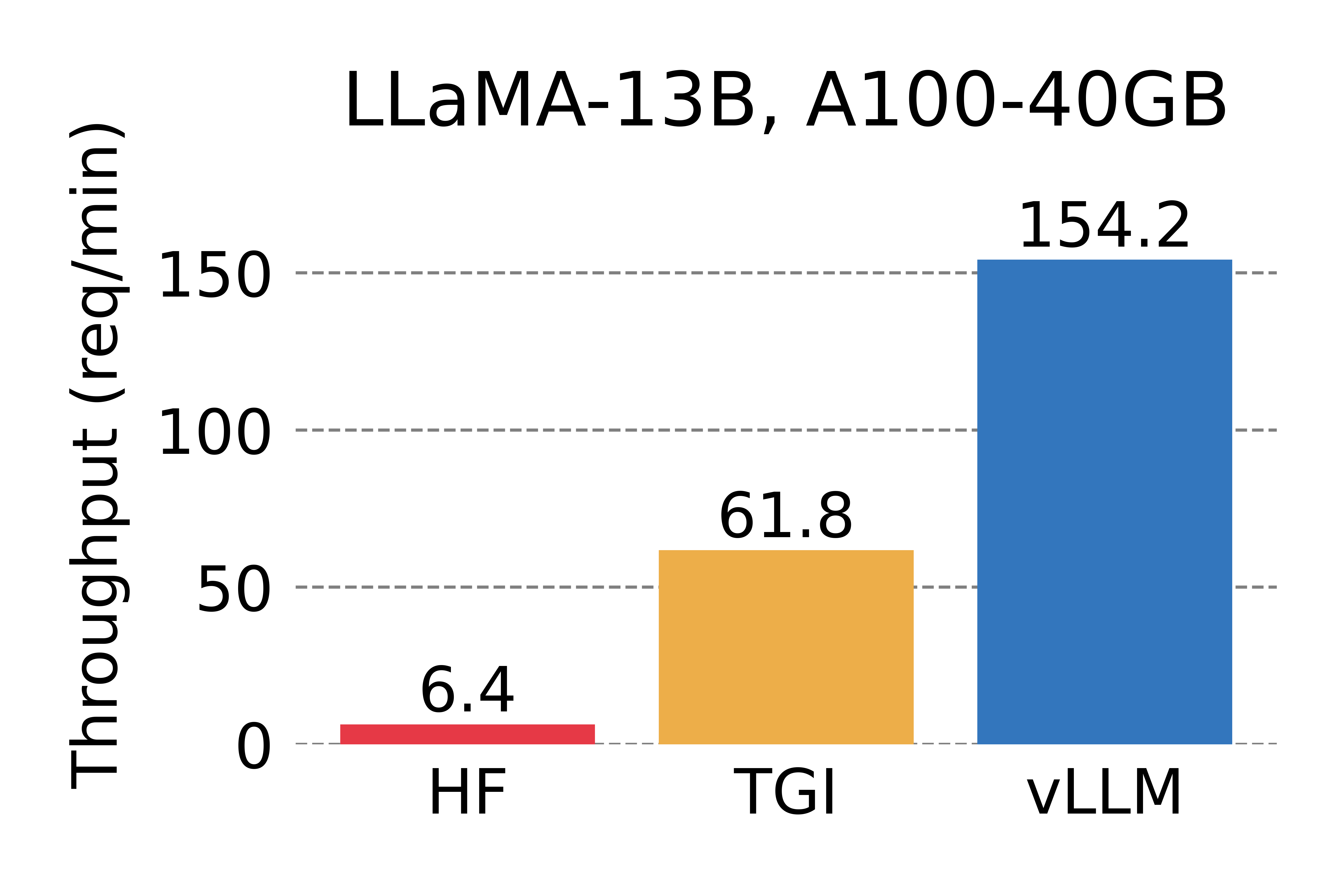 vLLM 吞吐量对比:A100 GPU
vLLM 吞吐量对比:A100 GPU
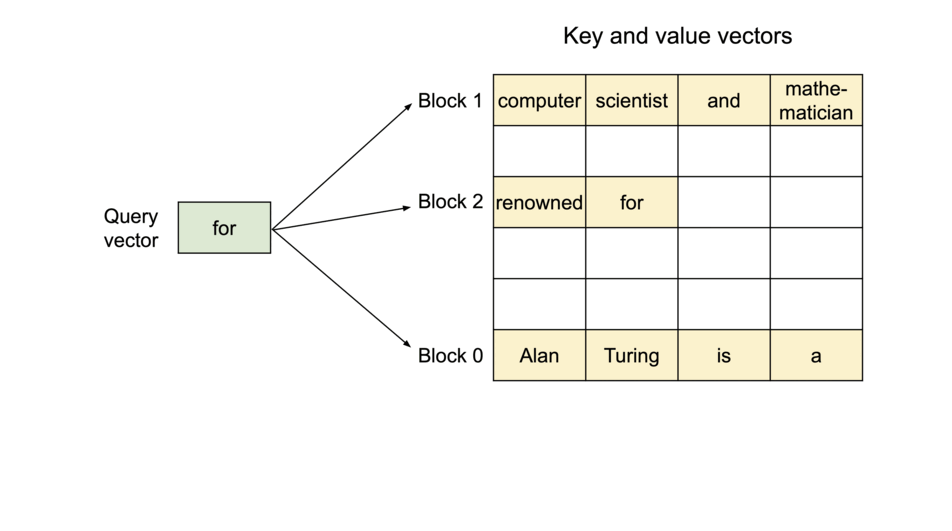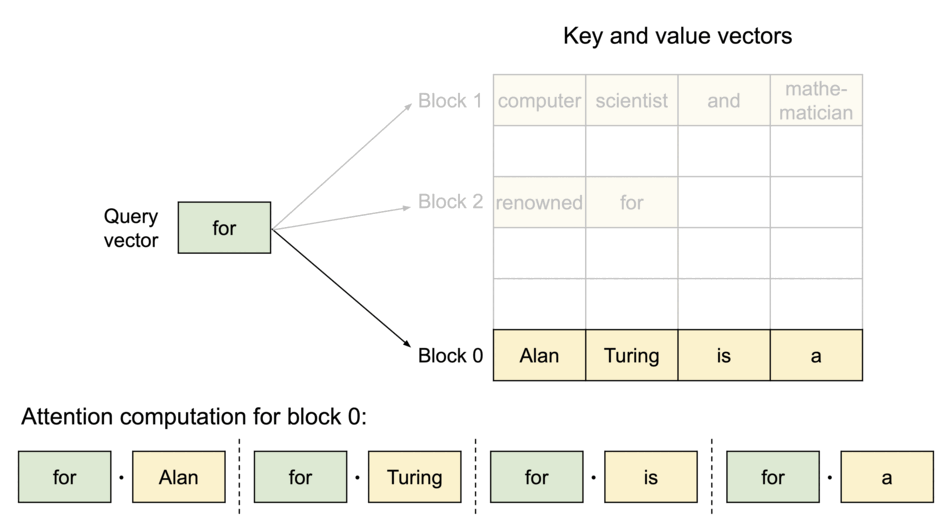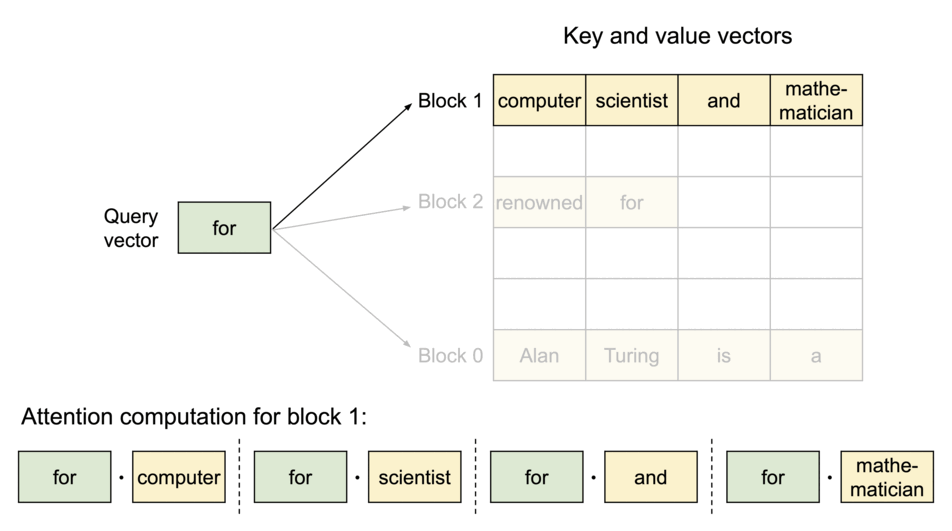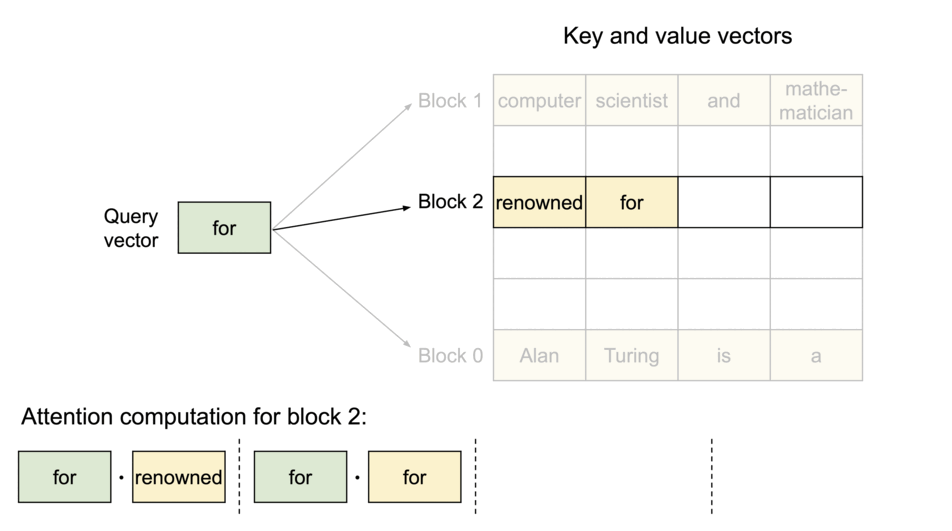 PagedAttention:KV Cache 分块存储
PagedAttention:KV Cache 分块存储
python
from vllm import LLM, SamplingParams
# 加载模型
llm = LLM(
model="meta-llama/Llama-2-7b-chat-hf",
tensor_parallel_size=1, # GPU数量
gpu_memory_utilization=0.9
)
# 采样参数
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=512
)
# 批量推理
prompts = ["你好", "介绍一下人工智能"]
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
print(output.outputs[0].text)vLLM核心优化
| 技术 | 说明 |
|---|---|
| PagedAttention | 类似虚拟内存管理KV Cache,显存浪费 < 4% |
| Continuous Batching | 动态批处理,提升吞吐 |
| Tensor Parallelism | 多GPU并行 |
| Prefix Caching | 缓存共享前缀 |
| Copy-on-Write | 并行采样共享 Prompt KV Cache |
性能对比:
| 对比 | 吞吐量提升 |
|---|---|
| vs HuggingFace Transformers | 14-24× |
| vs HuggingFace TGI | 2.2-3.5× |
实际部署数据(LMSYS):
- 日均处理 3万+ 请求,峰值 6万
- GPU 使用量减少 50%
💻 本地部署
llama.cpp部署
bash
# 1. 克隆并编译
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
# 2. 转换模型为GGUF格式
python convert_hf_to_gguf.py /path/to/model --outfile model.gguf
# 3. 量化
./llama-quantize model.gguf model-q4_k_m.gguf Q4_K_M
# 4. 运行推理
./llama-cli -m model-q4_k_m.gguf -p "你好" -n 128GGUF量化级别
| 量化类型 | 大小(7B) | 质量 | 推荐 |
|---|---|---|---|
| Q2_K | ~2.5GB | 较差 | 极限压缩 |
| Q4_K_M | ~4GB | 良好 | ✅ 推荐 |
| Q5_K_M | ~5GB | 很好 | 精度优先 |
| Q8_0 | ~7GB | 最佳 | 不追求压缩 |
Ollama快速部署
bash
# 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 运行模型
ollama run llama2
# 或使用自定义模型
ollama create mymodel -f Modelfile
ollama run mymodel✂️ 模型剪枝
结构化剪枝
python
import torch.nn.utils.prune as prune
def prune_model(model, amount=0.3):
"""对模型进行剪枝"""
for name, module in model.named_modules():
if isinstance(module, torch.nn.Linear):
prune.l1_unstructured(module, name='weight', amount=amount)
prune.remove(module, 'weight')
return model知识蒸馏
python
from transformers import DistilBertForSequenceClassification
# 教师模型(大模型)
teacher = AutoModelForCausalLM.from_pretrained("large_model")
# 学生模型(小模型)
student = AutoModelForCausalLM.from_pretrained("small_model")
# 蒸馏损失
def distillation_loss(student_logits, teacher_logits, temperature=2.0):
soft_targets = F.softmax(teacher_logits / temperature, dim=-1)
soft_predictions = F.log_softmax(student_logits / temperature, dim=-1)
return F.kl_div(soft_predictions, soft_targets, reduction='batchmean')📊 推理框架对比
| 框架 | 特点 | 适用场景 |
|---|---|---|
| vLLM | PagedAttention,高吞吐 | 生产服务 |
| TGI | HuggingFace官方 | 企业部署 |
| llama.cpp | CPU推理,GGUF格式 | 本地/边缘 |
| Ollama | 开箱即用 | 快速体验 |
| TensorRT-LLM | NVIDIA优化 | 追求极致性能 |
🔗 相关阅读
相关文章:
外部资源: