训练数据处理
"垃圾进,垃圾出"——数据质量决定模型上限
🎯 核心原则
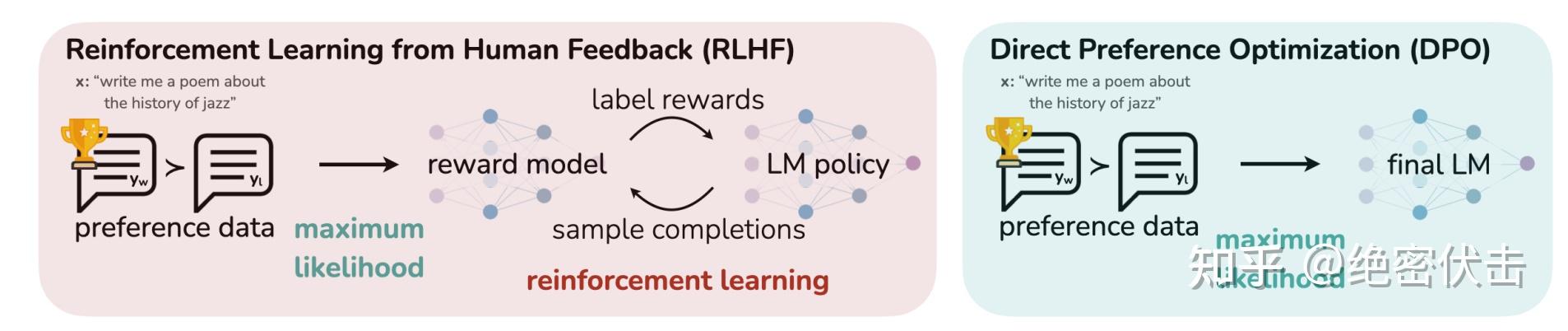 数据是 LLM 训练的基石
数据是 LLM 训练的基石
关键洞察
微调大语言模型的核心在于高质量数据。研究表明:
- 高质量的 1,000 条数据 > 低质量的 100,000 条数据
- 数据多样性比数量更重要
- 混入 5-10% 通用数据可防止灾难性遗忘
数据质量维度
| 维度 | 说明 | 检查方法 |
|---|---|---|
| 准确性 | 内容正确无误 | 专家审核、事实核查 |
| 相关性 | 响应切题 | 指令-响应匹配度 |
| 多样性 | 覆盖广泛 | 聚类分析、嵌入可视化 |
| 一致性 | 风格统一 | 模板检查、格式验证 |
| 安全性 | 无有害内容 | 敏感词过滤、人工审核 |
📊 数据格式
SFT 数据集格式至关重要
SFT 数据集需包含明确的结构:
- 指令(Instruction):任务描述
- 输入(Input):可选的上下文信息
- 期望输出(Output):标准答案
- 若需多语言理解或复杂上下文处理,还需标注对话历史和角色身份
主流格式对比
| 格式 | 结构 | 适用场景 | 特点 |
|---|---|---|---|
| Alpaca | instruction/input/output | 单轮指令任务 | 简单直观,适合问答、翻译 |
| ShareGPT | conversations数组 | 多轮对话 | 保留完整对话历史 |
| OpenAI | messages数组(system/user/assistant) | 通用格式 | API 兼容,支持系统提示 |
Alpaca格式
json
{
"instruction": "将以下英文翻译成中文",
"input": "Hello, how are you?",
"output": "你好,你好吗?"
}ShareGPT格式
json
{
"conversations": [
{"from": "human", "value": "你好,请介绍一下自己"},
{"from": "gpt", "value": "你好!我是一个AI助手..."},
{"from": "human", "value": "你能做什么?"},
{"from": "gpt", "value": "我可以帮助你回答问题..."}
]
}OpenAI格式
json
{
"messages": [
{"role": "system", "content": "你是一个有帮助的助手"},
{"role": "user", "content": "你好"},
{"role": "assistant", "content": "你好!有什么可以帮助你的吗?"}
]
}🔧 数据处理流程
完整流程图
原始数据
│
▼
┌─────────────┐
│ 数据清洗 │ → 去除噪声、修复格式错误、规范化空白字符
└─────────────┘
│
▼
┌─────────────┐
│ PII脱敏 │ → 匿名化个人隐私信息(邮箱、电话、身份证)
└─────────────┘
│
▼
┌─────────────┐
│ 质量过滤 │ → 过滤低质量样本(长度、重复、语言检查)
└─────────────┘
│
▼
┌─────────────┐
│ 去重处理 │ → 基于嵌入的语义去重(超级过滤)
└─────────────┘
│
▼
┌─────────────┐
│ 格式转换 │ → 转为目标训练格式(Alpaca/ShareGPT/OpenAI)
└─────────────┘
│
▼
┌─────────────┐
│ 数据增强 │ → 使用 GPT-4 生成、回译、同义词替换
└─────────────┘
│
▼
┌─────────────┐
│ 混合策略 │ → 混入 5-10% 通用数据防止灾难性遗忘
└─────────────┘
│
▼
训练数据集数据构建最佳实践
| 实践 | 说明 |
|---|---|
| GPT-4 生成 | 利用强 LLM 生成、过滤高质量数据,提升数据质量与多样性 |
| 人工审核 | 关键数据需专家审核,确保准确性 |
| 多样性检查 | 通过嵌入聚类分析,确保数据覆盖广泛 |
| 混合通用数据 | 领域微调时混入 5-10% 通用数据,防止 CF |
数据清洗
python
import re
def clean_text(text: str) -> str:
"""清洗文本数据"""
# 1. 去除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 2. 规范化空白字符
text = re.sub(r'\s+', ' ', text)
# 3. 去除特殊控制字符
text = ''.join(c for c in text if c.isprintable() or c in '\n\t')
# 4. 修复编码问题
text = text.encode('utf-8', errors='ignore').decode('utf-8')
return text.strip()
def filter_low_quality(samples: list) -> list:
"""过滤低质量样本"""
filtered = []
for sample in samples:
# 长度检查
if len(sample.get('output', '')) < 10:
continue
# 重复检查
if sample.get('output', '') == sample.get('input', ''):
continue
# 语言检查(可选)
if not is_valid_language(sample.get('output', '')):
continue
filtered.append(sample)
return filteredPII脱敏
python
import re
class PIIAnonymizer:
"""个人隐私信息脱敏"""
PATTERNS = {
'email': r'\b[\w.-]+@[\w.-]+\.\w+\b',
'phone': r'\b1[3-9]\d{9}\b',
'id_card': r'\b\d{17}[\dXx]\b',
'ip': r'\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b',
}
def anonymize(self, text: str) -> str:
for pii_type, pattern in self.PATTERNS.items():
text = re.sub(pattern, f'[{pii_type.upper()}]', text)
return text📈 数据质量评估
嵌入空间分析
python
from sentence_transformers import SentenceTransformer
from sklearn.cluster import KMeans
import numpy as np
def analyze_diversity(texts: list, n_clusters: int = 10):
"""分析数据集多样性"""
# 生成嵌入
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(texts)
# 聚类分析
kmeans = KMeans(n_clusters=n_clusters)
labels = kmeans.fit_predict(embeddings)
# 计算多样性指标
cluster_sizes = np.bincount(labels)
diversity_score = 1 - (cluster_sizes.std() / cluster_sizes.mean())
return {
"diversity_score": diversity_score,
"cluster_distribution": cluster_sizes.tolist(),
"largest_cluster_ratio": cluster_sizes.max() / len(texts)
}超级过滤技术
python
def super_filter(samples: list, threshold: float = 0.9) -> list:
"""超级过滤:去除高度相似的样本"""
from sklearn.metrics.pairwise import cosine_similarity
model = SentenceTransformer('all-MiniLM-L6-v2')
texts = [s['instruction'] + s.get('input', '') for s in samples]
embeddings = model.encode(texts)
# 计算相似度矩阵
sim_matrix = cosine_similarity(embeddings)
# 去重
keep_indices = []
for i in range(len(samples)):
is_duplicate = False
for j in keep_indices:
if sim_matrix[i][j] > threshold:
is_duplicate = True
break
if not is_duplicate:
keep_indices.append(i)
return [samples[i] for i in keep_indices]🗄️ Parquet格式优化
为什么使用Parquet?
| 指标 | CSV/JSON | Parquet | 提升 |
|---|---|---|---|
| 存储空间 | 100% | 13% | 87%↓ |
| 查询速度 | 1x | 34.8x | 34.8x↑ |
| 数据扫描 | 100% | 0.2% | 99.8%↓ |
转换示例
python
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pq
def json_to_parquet(json_path: str, parquet_path: str):
"""将JSON数据转换为Parquet格式"""
# 读取JSON
df = pd.read_json(json_path, lines=True)
# 转换为Parquet
table = pa.Table.from_pandas(df)
pq.write_table(
table,
parquet_path,
compression='snappy', # 压缩算法
row_group_size=10000 # 行组大小
)
def read_parquet_efficiently(parquet_path: str, columns: list = None):
"""高效读取Parquet(列裁剪)"""
return pq.read_table(
parquet_path,
columns=columns # 只读取需要的列
).to_pandas()🏷️ 特殊Token与模板
关键警告
90%的微调性能下降可归因于训练与推理阶段模板结构不一致!
常见特殊Token
| Token | 作用 | 示例 |
|---|---|---|
<s> / <bos> | 序列开始 | 标记输入起点 |
</s> / <eos> | 序列结束 | 标记输出终点 |
[INST] / [/INST] | 指令边界 | Llama格式 |
| `< | im_start | >/< |
ChatML模板示例
<|im_start|>system
你是一个有帮助的AI助手。<|im_end|>
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant
你好!有什么可以帮助你的吗?<|im_end|>模板匹配检查
python
def validate_template_consistency(train_template: str, infer_template: str) -> bool:
"""验证训练和推理模板一致性"""
# 提取特殊Token
train_tokens = set(re.findall(r'<\|?\w+\|?>', train_template))
infer_tokens = set(re.findall(r'<\|?\w+\|?>', infer_template))
if train_tokens != infer_tokens:
print(f"警告:Token不一致!")
print(f"训练: {train_tokens}")
print(f"推理: {infer_tokens}")
return False
return True🔗 相关阅读
相关文章:
外部资源: