RLHF 人类反馈强化学习
从"能回答"到"会回答"的价值对齐
🎯 核心概念
来源:RLHF之PPO、DPO详解 | DPO原理深度解析 | RLHF技术问答
什么是RLHF?
定义
RLHF(Reinforcement Learning from Human Feedback) 是一种通过人类偏好数据训练奖励模型,再用强化学习优化语言模型的技术,使模型输出更符合人类价值观和期望。
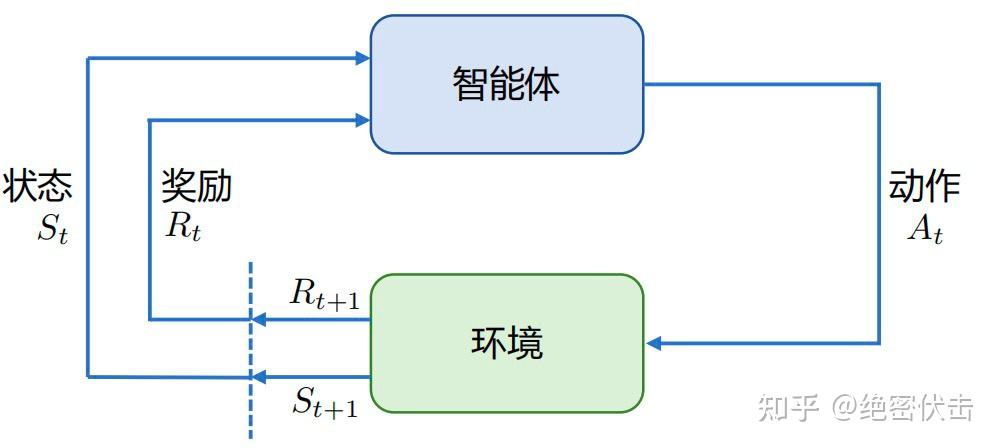 强化学习基本框架:智能体与环境交互
强化学习基本框架:智能体与环境交互
为什么需要RLHF?
根据 OpenAI 联合创始人 John Schulman 在 Berkeley EECS 的报告,强化学习在大语言模型上的重要作用:
| 优势 | SFT(监督微调) | 强化学习 |
|---|---|---|
| 反馈粒度 | 针对单个 Token | 针对整个输出文本 |
| 表达多样性 | 要求确切答案 | 兼顾多样性 |
| 幻觉问题 | 易导致模型强行回答 | 可通过奖励设计让模型学会"拒绝回答" |
| 多轮对话 | 难以考虑整体对话目标 | 可建模多轮交互的累积奖励 |
| 阶段 | 问题 | RLHF解决方案 |
|---|---|---|
| SFT后 | 会回答,但不知道哪个更好 | 学习人类偏好 |
| 多个正确答案 | 无法区分优劣 | 奖励模型打分 |
| 安全对齐 | 可能生成有害内容 | 惩罚不当输出 |
🔄 RLHF三阶段流程
┌─────────────────────────────────────────────────────────────────────┐
│ RLHF 三阶段流程 │
├─────────────────┬─────────────────┬─────────────────────────────────┤
│ 阶段一 │ 阶段二 │ 阶段三 │
│ 监督微调(SFT) │ 奖励模型(RM) │ 强化学习(PPO) │
├─────────────────┼─────────────────┼─────────────────────────────────┤
│ │ │ │
│ 指令数据集 │ 偏好数据集 │ SFT模型 + RM │
│ ↓ │ ↓ │ ↓ │
│ 监督学习 │ 对比学习 │ 策略优化 │
│ ↓ │ ↓ │ ↓ │
│ SFT模型 │ 奖励模型 │ 对齐模型 │
│ │ │ │
└─────────────────┴─────────────────┴─────────────────────────────────┘阶段一:监督微调(SFT)
python
# 使用高质量指令数据进行监督微调
# 详见 /training/sft 页面阶段二:奖励模型训练
python
from transformers import AutoModelForSequenceClassification
from trl import RewardTrainer, RewardConfig
# 1. 准备偏好数据
# 格式: {"prompt": "...", "chosen": "好回答", "rejected": "差回答"}
# 2. 加载奖励模型
reward_model = AutoModelForSequenceClassification.from_pretrained(
"meta-llama/Llama-2-7b-hf",
num_labels=1 # 输出单一分数
)
# 3. 配置训练
reward_config = RewardConfig(
output_dir="./reward_model",
per_device_train_batch_size=4,
num_train_epochs=1,
learning_rate=1e-5,
)
# 4. 训练奖励模型
trainer = RewardTrainer(
model=reward_model,
args=reward_config,
train_dataset=preference_dataset,
tokenizer=tokenizer,
)
trainer.train()阶段三:PPO强化学习
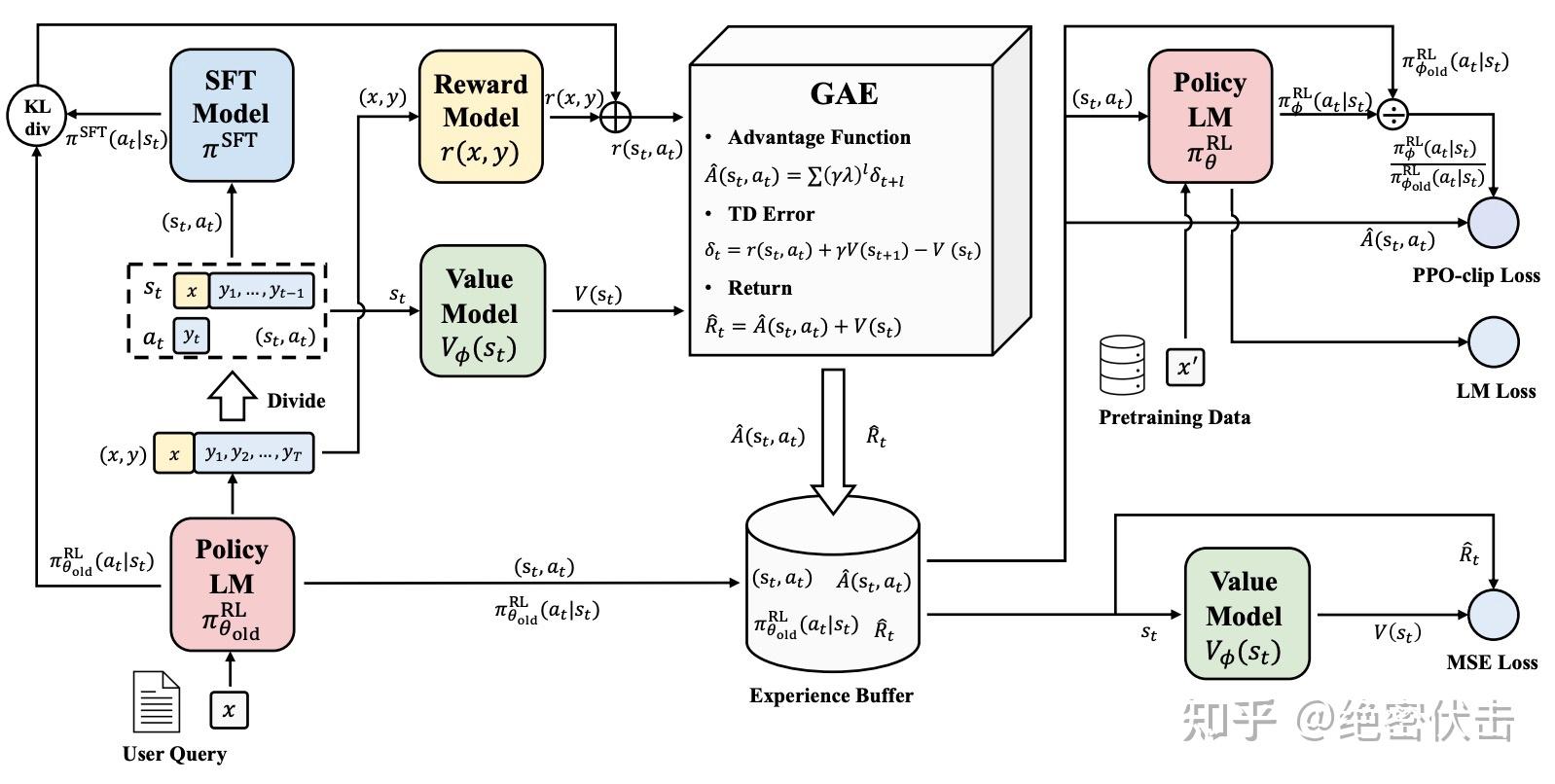 PPO 算法实施流程
PPO 算法实施流程
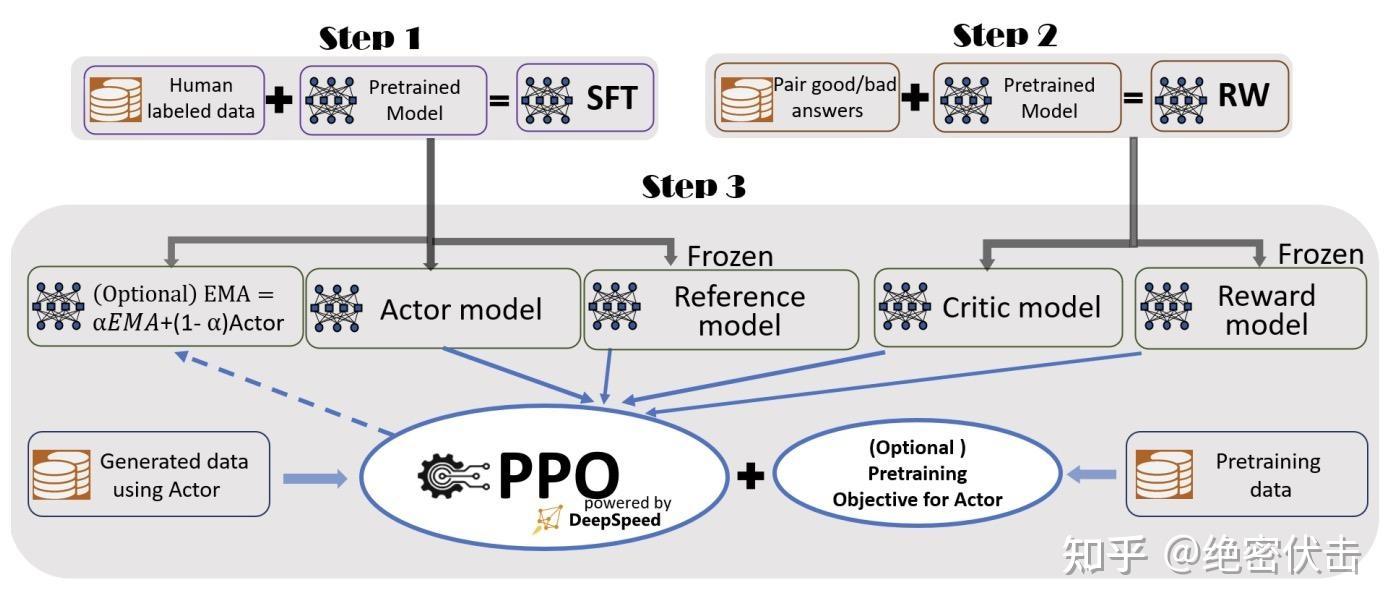 PPO 训练流程详解
PPO 训练流程详解
python
from trl import PPOTrainer, PPOConfig, AutoModelForCausalLMWithValueHead
# 1. 加载模型
model = AutoModelForCausalLMWithValueHead.from_pretrained("sft_model")
ref_model = AutoModelForCausalLMWithValueHead.from_pretrained("sft_model")
# 2. PPO配置
ppo_config = PPOConfig(
learning_rate=1e-5,
batch_size=16,
mini_batch_size=4,
gradient_accumulation_steps=4,
ppo_epochs=4,
kl_penalty="kl", # KL散度惩罚
init_kl_coef=0.2, # KL系数
target_kl=6.0, # 目标KL值
)
# 3. 创建PPO训练器
ppo_trainer = PPOTrainer(
model=model,
ref_model=ref_model,
config=ppo_config,
tokenizer=tokenizer,
dataset=dataset,
)
# 4. 训练循环
for batch in dataloader:
# 生成响应
query_tensors = batch["input_ids"]
response_tensors = ppo_trainer.generate(query_tensors)
# 计算奖励
rewards = reward_model(response_tensors)
# PPO更新
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)🏗️ PPO四模型架构
┌─────────────────────────────────────────────────────────────────┐
│ PPO 四模型架构 │
├─────────────────┬─────────────────┬─────────────────┬───────────┤
│ 策略模型 │ 价值模型 │ 奖励模型 │ 参考模型 │
│ (Policy) │ (Value) │ (Reward) │ (Ref) │
├─────────────────┼─────────────────┼─────────────────┼───────────┤
│ 生成响应 │ 预测回报 │ 评估质量 │ KL约束 │
│ 待训练 │ 待训练 │ 冻结 │ 冻结 │
└─────────────────┴─────────────────┴─────────────────┴───────────┘各模型作用
| 模型 | 作用 | 是否训练 |
|---|---|---|
| 策略模型 | 生成响应,是最终要优化的模型 | ✅ 训练 |
| 价值模型 | 预测未来累积奖励,辅助策略优化 | ✅ 训练 |
| 奖励模型 | 对响应质量打分 | ❌ 冻结 |
| 参考模型 | SFT模型副本,用于计算KL散度 | ❌ 冻结 |
KL散度约束
重要
KL散度约束防止策略模型偏离参考模型太远,避免"奖励hacking"(模型找到奖励模型漏洞而非真正改进)。
python
# KL散度计算
kl_divergence = log(policy_prob / ref_prob)
# 最终奖励 = 原始奖励 - KL惩罚
final_reward = reward - kl_coef * kl_divergence⚙️ 关键超参数
| 参数 | 推荐值 | 说明 |
|---|---|---|
| learning_rate | 1e-6 ~ 1e-5 | PPO学习率,比SFT更低 |
| kl_coef | 0.1 ~ 0.2 | KL惩罚系数 |
| target_kl | 6.0 | 目标KL值,超过则停止 |
| ppo_epochs | 2-4 | 每批数据的PPO更新次数 |
| clip_range | 0.2 | PPO裁剪范围 |
| vf_coef | 0.1 | 价值函数损失系数 |
🚀 简化方案:DPO
详见 DPO直接偏好优化 页面
RLHF的主要挑战:
- 需要训练4个模型
- 训练不稳定
- 计算成本高
DPO(Direct Preference Optimization) 通过直接优化偏好数据,无需奖励模型:
python
# DPO只需要:偏好数据 + 策略模型 + 参考模型
# 详见 dpo.md🔗 相关阅读
相关文章:
外部资源: