模型评估
科学度量模型能力与训练效果
🎯 评估维度
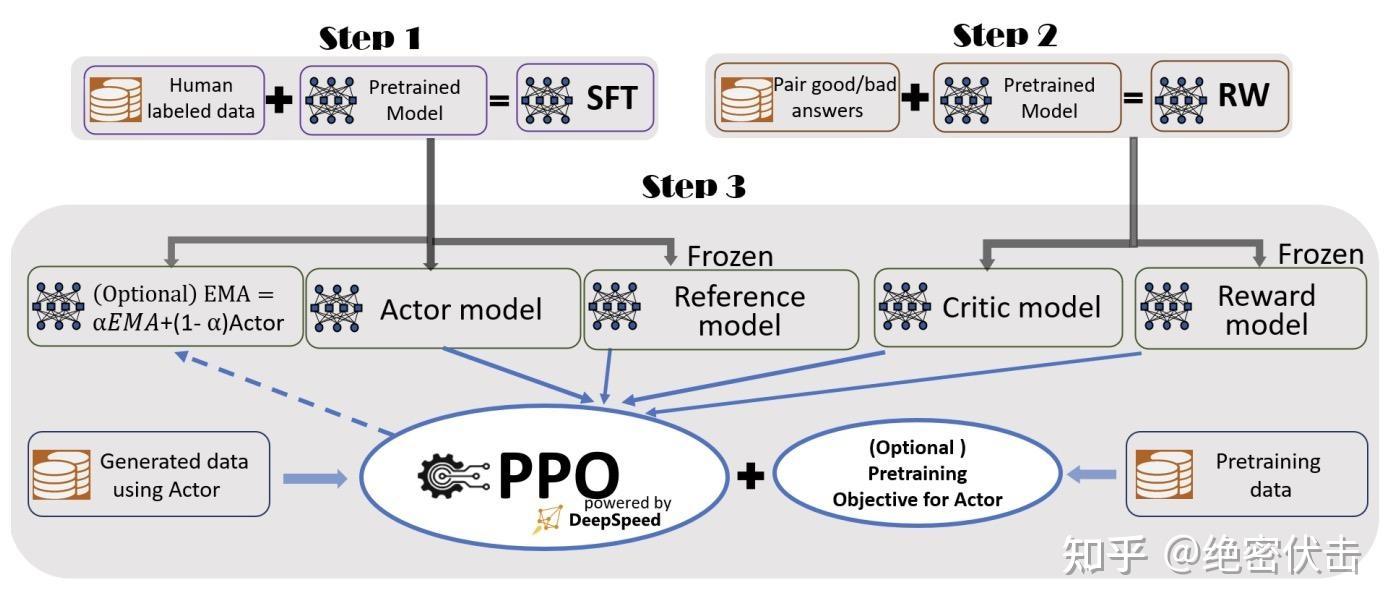 LLM 训练与评估流程
LLM 训练与评估流程
评估目标
| 维度 | 评估内容 | 关键指标 |
|---|---|---|
| 语言能力 | 理解、生成、推理 | Perplexity、BLEU |
| 知识水平 | 事实准确性 | 基准测试得分 |
| 指令遵循 | 按要求完成任务 | 任务完成率 |
| 安全性 | 有害内容、偏见 | 安全评分 |
| 实用性 | 人类满意度 | 人工评估 |
评估时机
| 阶段 | 评估重点 | 方法 |
|---|---|---|
| 预训练 | 语言建模能力 | Perplexity、下游任务零样本 |
| SFT 后 | 指令遵循能力 | 任务完成率、BLEU/ROUGE |
| RLHF 后 | 人类偏好对齐 | 人工评估、奖励模型得分 |
| 部署前 | 安全性、幻觉 | 红队测试、TruthfulQA |
📊 自动评估指标
语言质量
python
from evaluate import load
# 1. Perplexity - 困惑度
perplexity = load("perplexity")
results = perplexity.compute(
predictions=["生成的文本"],
model_id="gpt2"
)
print(f"Perplexity: {results['mean_perplexity']}")
# 2. BLEU - 机器翻译质量
bleu = load("bleu")
results = bleu.compute(
predictions=["生成的翻译"],
references=[["参考翻译1", "参考翻译2"]]
)
print(f"BLEU: {results['bleu']}")
# 3. ROUGE - 摘要质量
rouge = load("rouge")
results = rouge.compute(
predictions=["生成的摘要"],
references=["参考摘要"]
)
print(f"ROUGE-L: {results['rougeL']}")生成质量
| 指标 | 评估内容 | 适用场景 |
|---|---|---|
| Perplexity | 语言模型困惑度 | 语言流畅性 |
| BLEU | n-gram精确匹配 | 翻译、问答 |
| ROUGE | 召回率导向 | 摘要 |
| BERTScore | 语义相似度 | 通用文本生成 |
| METEOR | 词干匹配+同义词 | 翻译 |
python
# BERTScore - 语义相似度
from bert_score import score
P, R, F1 = score(
cands=["生成的文本"],
refs=["参考文本"],
lang="zh"
)
print(f"BERTScore F1: {F1.mean()}")🏆 基准测试
基准测试分类
┌─────────────────────────────────────────────────────────────┐
│ LLM 评估基准 │
├─────────────────┬─────────────────┬─────────────────────────┤
│ 知识理解 │ 推理能力 │ 安全与对齐 │
├─────────────────┼─────────────────┼─────────────────────────┤
│ MMLU/C-Eval │ GSM8K/MATH │ TruthfulQA │
│ CMMLU/GAOKAO │ ARC/HellaSwag │ 红队测试 │
│ TriviaQA │ BBH │ 偏见检测 │
└─────────────────┴─────────────────┴─────────────────────────┘中文基准
| 基准 | 评估内容 | 说明 | 难度 |
|---|---|---|---|
| C-Eval | 中文综合能力 | 52 个学科,1.4 万题 | 中高 |
| CMMLU | 中文多任务 | 67 个主题 | 中 |
| GAOKAO | 高考题目 | 真实考试场景 | 高 |
| AGIEval | 人类考试 | 法考、公务员等 | 高 |
英文基准
| 基准 | 评估内容 | 说明 | 难度 |
|---|---|---|---|
| MMLU | 多任务理解 | 57 个学科 | 中高 |
| HellaSwag | 常识推理 | 完成句子 | 中 |
| ARC | 科学推理 | 小学科学题 | 中 |
| TruthfulQA | 真实性 | 抗幻觉能力 | 高 |
| GSM8K | 数学推理 | 小学数学题 | 中 |
| HumanEval | 代码生成 | 编程能力 | 高 |
| MATH | 数学竞赛 | 高难度数学 | 极高 |
使用lm-evaluation-harness
bash
# 安装
pip install lm-eval
# 运行评估
lm_eval --model hf \
--model_args pretrained=meta-llama/Llama-2-7b-hf \
--tasks mmlu,hellaswag,arc_easy \
--batch_size 8 \
--output_path ./resultspython
# Python API
from lm_eval import evaluator
results = evaluator.simple_evaluate(
model="hf",
model_args="pretrained=meta-llama/Llama-2-7b-hf",
tasks=["mmlu", "hellaswag"],
batch_size=8
)
print(results["results"])👥 人工评估
为什么需要人工评估
| 问题 | 说明 |
|---|---|
| 自动指标局限 | BLEU/ROUGE 与人类判断相关性有限 |
| 主观性任务 | 创意写作、对话质量难以量化 |
| 安全性检测 | 有害内容需人工判断 |
| 偏好对齐验证 | RLHF 效果需人类反馈 |
评估维度
| 维度 | 评分标准 | 说明 |
|---|---|---|
| 相关性 | 1-5分 | 回答是否切题 |
| 准确性 | 1-5分 | 信息是否正确 |
| 流畅性 | 1-5分 | 表达是否自然 |
| 有帮助性 | 1-5分 | 是否解决问题 |
| 安全性 | 是/否 | 是否存在有害内容 |
| 一致性 | 1-5分 | 多轮对话是否连贯 |
对比评估(A/B Test)
python
def pairwise_comparison(response_a: str, response_b: str, prompt: str):
"""让评估者选择更好的回答"""
evaluation_prompt = f"""
请比较以下两个回答,选择更好的一个:
问题:{prompt}
回答A:{response_a}
回答B:{response_b}
请输出 "A" 或 "B" 或 "平手",并说明理由。
"""
return evaluation_prompt使用LLM作为评估者
python
def llm_as_judge(response: str, reference: str, criteria: str):
"""使用LLM评估响应质量"""
prompt = f"""请根据以下标准评估回答质量,给出1-10分:
评估标准:{criteria}
参考答案:{reference}
待评估回答:{response}
请输出:
分数:[1-10]
理由:[简要说明]
"""
return llm.generate(prompt)📈 训练监控指标
训练曲线
python
# 关键监控指标
training_metrics = {
"train_loss": "训练损失,应持续下降",
"eval_loss": "验证损失,关注是否过拟合",
"learning_rate": "学习率变化",
"grad_norm": "梯度范数,检测梯度爆炸",
"reward": "RLHF 阶段的奖励信号",
"kl_divergence": "策略与参考模型的 KL 散度",
}
# TensorBoard可视化
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("./logs")
writer.add_scalar("train/loss", loss, step)
writer.add_scalar("eval/loss", eval_loss, step)过拟合检测
| 训练损失 | 验证损失 | 状态 | 建议 |
|---|---|---|---|
| ↓ | ↓ | ✅ 正常学习 | 继续训练 |
| ↓ | ↑ | ❌ 过拟合 | 早停、正则化、减少 epoch |
| → | → | ⚠️ 学习停滞 | 调大学习率、检查数据 |
| ↑ | ↑ | ❌ 训练失败 | 减小学习率、检查梯度 |
SFT 特有监控
| 指标 | 说明 | 正常范围 |
|---|---|---|
| Loss | 交叉熵损失 | 持续下降,最终 1.5-2.5 |
| Perplexity | 困惑度 | 5-15(取决于任务) |
| Token Accuracy | Token 级准确率 | 逐步提升 |
| Generation Quality | 生成样本质量 | 定期人工检查 |
🔄 评估流程
┌─────────────────────────────────────────────────────┐
│ 评估流程 │
├─────────────────┬─────────────────┬─────────────────┤
│ 自动评估 │ 基准测试 │ 人工评估 │
├─────────────────┼─────────────────┼─────────────────┤
│ BLEU/ROUGE │ MMLU/C-Eval │ A/B对比 │
│ BERTScore │ GSM8K │ 多维度打分 │
│ Perplexity │ HellaSwag │ LLM-as-Judge │
└─────────────────┴─────────────────┴─────────────────┘🔍 LLM-as-Judge 详解
为什么使用 LLM 作为评估者
| 方法 | 优点 | 缺点 |
|---|---|---|
| 人工评估 | 最准确 | 成本高、速度慢 |
| 自动指标 | 快速、可复现 | 与人类判断相关性低 |
| LLM-as-Judge | 平衡成本与质量 | 可能有偏见 |
常见评估模式
python
# 1. 单点评分(Point-wise)
def pointwise_eval(response, criteria):
prompt = f"""请根据以下标准评估回答,给出 1-10 分:
标准:{criteria}
回答:{response}
输出格式:
分数:[1-10]
理由:[简要说明]"""
return llm.generate(prompt)
# 2. 对比评估(Pairwise)
def pairwise_eval(response_a, response_b, question):
prompt = f"""比较以下两个回答,选择更好的一个:
问题:{question}
回答A:{response_a}
回答B:{response_b}
输出:A 或 B 或 平手"""
return llm.generate(prompt)
# 3. 参考对比(Reference-guided)
def reference_eval(response, reference, criteria):
prompt = f"""参考标准答案评估回答质量:
标准答案:{reference}
待评估:{response}
评估标准:{criteria}"""
return llm.generate(prompt)🔗 相关阅读
相关文章:
外部资源: