LoRA 高效微调
让消费级显卡也能微调大模型
🎯 核心概念
来源:Fine-Tuning using LoRA and QLoRA - GeeksforGeeks | PEFT技术深度解析
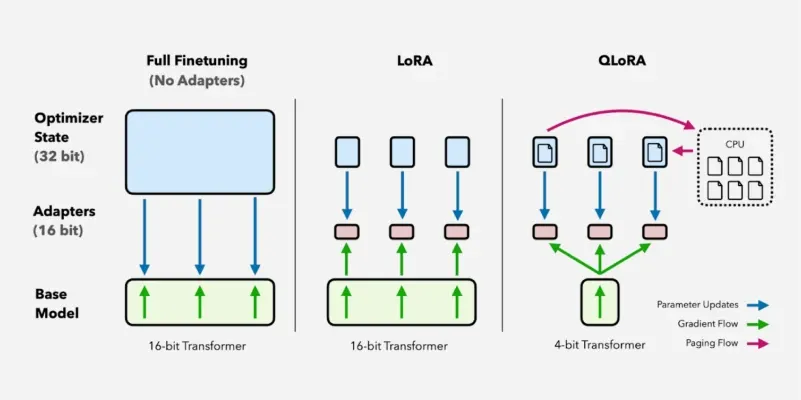 LoRA vs QLoRA 对比
LoRA vs QLoRA 对比
什么是LoRA?
定义
LoRA(Low-Rank Adaptation) 是一种参数高效微调(PEFT)技术,通过在预训练权重旁边注入可训练的低秩矩阵,仅更新 0.5-5% 的参数即可达到接近全量微调的效果。
传统微调 vs LoRA
 Simple vs Base vs Fine-Tuned Model
Simple vs Base vs Fine-Tuned Model
传统微调(Full Fine-Tuning):更新预训练模型的全部或大部分参数。对于拥有数十亿参数的模型,这需要大量 GPU 算力、显存和时间,对硬件要求极高。
LoRA 微调:仅更新注入的低秩矩阵,大幅降低计算和显存需求。
LoRA 原理
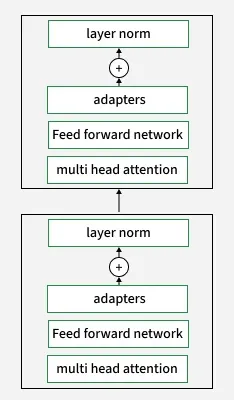 Adapter Layer in LoRA
Adapter Layer in LoRA
原始权重 W (d×k) LoRA分解
│ │
│ ┌──────┴──────┐
│ │ │
▼ ▼ ▼
冻结 B (d×r) A (r×k)
│ │ │
│ └──────┬──────┘
│ │
▼ ▼
W·x + B·A·x
│ │
└────────┬─────────┘
│
▼
W·x + B·A·x (r << d, k)核心思想:
- 在 Transformer 的每个块中插入小型 Adapter 模块
- Adapter 使用低秩矩阵实现
- 微调时只更新 Adapter 参数,核心模型权重(Multi-Head Attention、FFN 等)保持冻结
- 权重更新矩阵 ΔW 分解为两个低秩矩阵的乘积:ΔW = B × A
LoRA 核心特性
| 特性 | 说明 |
|---|---|
| 参数高效微调 | 仅 0.5-5% 参数可训练,其余冻结 |
| 显存效率 | 1GB 模型仅需 2GB VRAM(全量微调需 16GB+) |
| 实现简单 | HuggingFace PEFT 库广泛支持 |
| 低过拟合风险 | 训练参数少,对小数据集友好 |
| 模块化 | Adapter 可热插拔,支持多任务部署 |
| 无推理延迟 | 训练后可合并到主模型,无额外推理开销 |
📊 PEFT方法对比
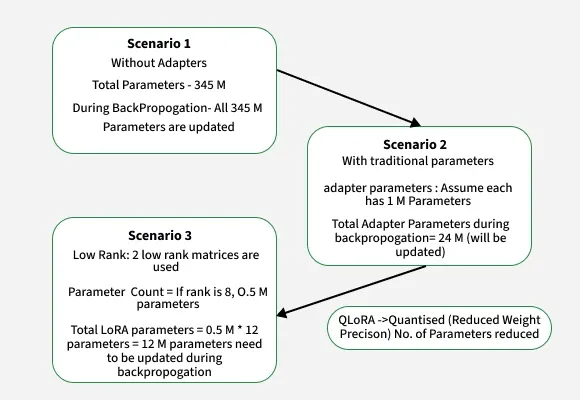 Full Fine-Tuning vs Adapter vs LoRA 参数量对比
Full Fine-Tuning vs Adapter vs LoRA 参数量对比
| 场景 | 可训练参数 | 说明 |
|---|---|---|
| Scenario 1: Full Fine-Tuning | 345M(100%) | 更新所有模型参数 |
| Scenario 2: Adapter Tuning | 24M(~7%) | 每层 1M × 24 层 |
| Scenario 3: LoRA | 12M(~3.5%) | 0.5M × 12 × 2 矩阵 |
| QLoRA | 更少 | LoRA + 4-bit 量化 |
| 方法 | 参数量 | 显存需求 | 训练速度 | 效果 |
|---|---|---|---|---|
| 全量微调(FFT) | 100% | 极高 | 慢 | 最佳 |
| LoRA | <1% | 低 | 快 | 接近FFT |
| QLoRA | <1% | 极低 | 中 | 接近LoRA |
| Adapter | ~3% | 中 | 中 | 良好 |
| Prefix Tuning | <1% | 低 | 快 | 中等 |
LoRA vs QLoRA
| 特性 | LoRA | QLoRA |
|---|---|---|
| 基座模型精度 | FP16/BF16 | 4-bit量化 |
| 显存占用 | 中等 | 极低 |
| 训练速度 | 快 | 稍慢 |
| 效果 | 最佳 | 接近LoRA |
| 适用场景 | 有GPU资源 | 消费级显卡 |
🔧 LoRA实现
使用PEFT库
python
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoModelForCausalLM, AutoTokenizer
# 1. 加载基座模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
torch_dtype=torch.float16,
device_map="auto"
)
# 2. 配置LoRA
lora_config = LoraConfig(
r=16, # 低秩维度
lora_alpha=32, # 缩放因子
target_modules=[ # 目标模块
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"
],
lora_dropout=0.05, # Dropout比例
bias="none", # 不训练偏置
task_type=TaskType.CAUSAL_LM # 任务类型
)
# 3. 应用LoRA
model = get_peft_model(model, lora_config)
# 4. 查看可训练参数
model.print_trainable_parameters()
# 输出: trainable params: 4,194,304 || all params: 6,742,609,920 || trainable%: 0.0622QLoRA(Quantized LoRA)
QLoRA 将基座模型以 4-bit 量化格式加载,大幅减少显存占用,同时以更高精度(如 16-bit)训练 LoRA 适配器。
QLoRA 核心特性:
| 特性 | 说明 |
|---|---|
| 进一步节省显存 | 使用 NF4 量化主模型权重为 4-bit,Adapter 保持 16-bit |
| 超低资源需求 | 可在消费级 GPU 甚至 CPU 上微调数十亿参数模型(1GB 模型仅需 ~0.5GB VRAM) |
| 保持精度 | 性能与标准 LoRA 和全量微调相当,损失可忽略 |
| Adapter 放置 | 对于大模型,建议将 LoRA 应用于所有线性层,不仅限于 Q/K/V |
| 双重量化 | 可进一步压缩存储,尤其是 scale/offset 常量 |
| 量化损失缓解 | LoRA 作为"补偿器"修正量化引入的误差 |
权衡:QLoRA 因量化/反量化步骤比 LoRA 稍慢,但显存节省显著,扩展性极强。
python
from transformers import BitsAndBytesConfig
from peft import prepare_model_for_kbit_training
# 1. 4-bit量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4", # NormalFloat4量化
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True # 双重量化
)
# 2. 加载量化模型
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=bnb_config,
device_map="auto"
)
# 3. 准备模型进行k-bit训练
model = prepare_model_for_kbit_training(model)
# 4. 应用LoRA(建议应用到所有线性层)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
target_modules="all-linear", # 对于 QLoRA,建议应用到所有线性层
lora_dropout=0.05,
bias="none",
task_type=TaskType.CAUSAL_LM
)
model = get_peft_model(model, lora_config)⚙️ 关键超参数
r(秩)
| r值 | 参数量 | 效果 | 建议场景 |
|---|---|---|---|
| 4 | 最少 | 够用 | 简单任务 |
| 8 | 较少 | 良好 | 一般任务 |
| 16 | 中等 | 很好 | 复杂任务(推荐) |
| 32 | 较多 | 最佳 | 追求极致效果 |
| 64+ | 很多 | 饱和 | 通常不必要 |
lora_alpha
python
# 实际缩放因子 = lora_alpha / r
# 常用配置:lora_alpha = 2 * r
lora_config = LoraConfig(
r=16,
lora_alpha=32, # 缩放因子2
# ...
)target_modules
| 模型 | 推荐目标模块 |
|---|---|
| LLaMA/Qwen | q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj |
| GPT-2 | c_attn, c_proj, c_fc |
| BLOOM | query_key_value, dense, dense_h_to_4h, dense_4h_to_h |
python
# 自动检测所有线性层
from peft.utils import TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING
# 或手动指定
target_modules = ["q_proj", "v_proj"] # 最小配置
target_modules = "all-linear" # 所有线性层📈 训练流程
完整训练脚本
python
from transformers import TrainingArguments
from trl import SFTTrainer
# 训练参数
training_args = TrainingArguments(
output_dir="./lora_output",
num_train_epochs=3,
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-4, # LoRA通常用更高学习率
warmup_ratio=0.03,
logging_steps=10,
save_strategy="epoch",
fp16=True,
optim="paged_adamw_8bit", # 8-bit优化器节省显存
gradient_checkpointing=True, # 梯度检查点
)
# 创建训练器
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
peft_config=lora_config,
max_seq_length=2048,
)
# 开始训练
trainer.train()
# 保存LoRA权重
model.save_pretrained("./lora_weights")合并权重
python
from peft import PeftModel
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
# 加载LoRA权重
model = PeftModel.from_pretrained(base_model, "./lora_weights")
# 合并权重
merged_model = model.merge_and_unload()
# 保存完整模型
merged_model.save_pretrained("./merged_model")🎯 最佳实践
显存优化
python
# 1. 使用梯度检查点
model.gradient_checkpointing_enable()
# 2. 使用8-bit优化器
training_args = TrainingArguments(
optim="paged_adamw_8bit",
# ...
)
# 3. 使用Flash Attention(如果支持)
model = AutoModelForCausalLM.from_pretrained(
model_name,
attn_implementation="flash_attention_2"
)多LoRA适配器
python
from peft import PeftModel
# 加载基座模型
base_model = AutoModelForCausalLM.from_pretrained("base_model")
# 加载多个LoRA适配器
model = PeftModel.from_pretrained(base_model, "lora_adapter_1")
model.load_adapter("lora_adapter_2", adapter_name="adapter2")
# 切换适配器
model.set_adapter("adapter2")
# 或合并多个适配器
model.add_weighted_adapter(
adapters=["default", "adapter2"],
weights=[0.7, 0.3],
adapter_name="merged"
)� 性能基准与发现
LoRA vs 全量微调
| 维度 | LoRA | 全量微调 |
|---|---|---|
| 参数量 | 0.2-0.3% | 100% |
| GLUE 分数 | 与全量微调差距 < 1% | 最佳 |
| 显存占用 | 降低 70% | 基准 |
| 适用场景 | 文本分类、摘要、问答等 | 复杂领域(数学、编程) |
发现:
- LoRA 在大多数任务上达到与全量微调相当的性能
- 全量微调在复杂领域(如数学、编程)仍有优势,但差距可通过超参数调优缩小
- LoRA 显存降低 70%,可在消费级 GPU 上部署
Adapter 效率权衡
| 维度 | Adapter | 说明 |
|---|---|---|
| 精度 | 与全量微调相当 | 适用于情感分析、法律文档处理等 |
| 推理延迟 | 增加 10-20% | 因额外层处理 |
| 计算需求 | 大幅降低 | 适合资源受限环境 |
�🔗 相关阅读
相关文章:
外部资源: